 |
Ile kosztuje czyjaś indywidualność? Minimum 2.77544 bitów
Ten wątek jest przedawniony
Działy Forum » Nauka
| Napisano | Autor | Tytuł | | 22-06-2012 21:41 | Jarek Duda (1185 punktów) | Ile kosztuje czyjaś indywidualność? Minimum 2.77544 bitów | Wyobraźmy sobie że jest jakaś populacja/baza danych/słownik i chcielibyśmy móc rozróżniać jej elementy. Więc dla każdego elementu jakoś kodujemy jego cechy indywidualne w ciąg bitów (np. funkcją haszującą). Najgęstszy sposób jest gdy bity są nieskorelowane i P(0)=P(1)=1/2. Dla tak utworzonych pseudolosowych ciągów bitów możemy teraz skonstruować minimalne drzewo prefixowe które by rozróżniały te sekwencje, jak na obrazku poniżej. Dla takiego zespołu drzew losowych o danej ilości liści (n), możemy policzyć entropię Shannona (H_n) - średnią ilość informacji którą ono zawiera. Okazuje się że asymptotycznie rośnie ona o 2.77544 bita na element (1/2+(1+gamma)lg(e)). Obliczenia są tutaj: arxiv.org/abs/1206.4555 Pierwsza myśl to że chodzi o n! gdy zwiększamy wielkość układu - nie, n! opisuje kolejność i jego logarytm rośnie szybciej niż liniowo. Ta indywidualność/rozróżnialność jest czymś dużo bardziej subtelnym. Dobrze to widać w równaniu (10) z pracy (które powinno wyglądać): H_n+\lg(n!)=nD_n gdzie D_n jest średnią głębokością liści - średnią ilością bitów wyróżniających element. Czyli to równanie mówi: rozróżnialność/indywidualność + porządek = całkowita ilość informacji rozróżnialność średnio rośnie liniowo z n (z asymptotycznym współczynnikiem 2.77544) informacja o porządku rośnie szybciej: lg(n!) ~= n lg(n) - n lg(e). Jak rozumieć taką minimalną ilość informacji potrzebną na rozróżnianie elementów układu? Czy można zaobserwować taki współczynnik wzrostu entropii z wzrostem populacji? Może ktoś się kiedyś spotkał z czymś podobnym? |
Autor wątku ma uprawnienia do usuwania wypowiedzi, jeżeli łamią regulamin Forum lub znacznie odbiegają od tematu.
| sceptymucha (moderator, 11470 punktów) |
>Okazuje się że asymptotycznie rośnie ona o 2.77544 bita na element (1/2+(1+gamma)lg(e)).
Co to znaczy? To znaczy, że kolejnych węzłów jest 2.77/2 raza więcej niż poprzednich, czy jak? (1.38 raza rozgałęzień na węzeł)
Pozdrawiam
Człowiek zawsze znajdzie coś nowego w obcym języku. Dziś poznałem nowe pojęcie:
"Negative IQ"
|
|
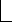 | | Jarek Duda (1185 punktów) | Rozgałęzień w sensie węzłów o stopniu 2 w drzewie binarnym o n liściach jest zawsze n-1.
Ilość węzłów o stopniu 1 lub 2 to ok. 1.4427n, czyli wszystkich jest ok. 2.4427n.
Rozumiem że chciałeś przyjąć że na węzeł przypada 1 bit informacji?
Niestety nie jest tak prosto - w reprezentacji której używam w pracy, wchodząc do węzła już wiemy ile to poddrzewo ma elementów (n: ile ciągów przechodzi przez ten węzeł) i kodujemy ile z nich pójdzie teraz w lewo (k) - reszta (n-k) pójdzie w prawo.
Rozkład w pojedynczym węźle to w przybliżeniu Gaussian i taki wybór kosztuje średnio
h_n=-sum_k (n po k)/2^n lg((n po k)/2^n)~= lg(pi*e*n/2)/2
Oczywiście można używać innych reprezentacji, ale każda ma dawać tą samą entropię - jest ona uniwersalnym parametrem.
Co taka entropia znaczy?
Bierzemy zespół prawdopodobieństwa możliwych "rozróżnialności" (w reprezentacji przez minimalne drzewa prefixowe) i liczymy entropię Shannona jak na obrazku:
-sum_i p_i lg(p_i)
Dla informatyka oznacza to że trzeba średnio 2.77544 bita na element żeby zapamiętać ich rozróżnialność.
Dla fizyka że entropia układu z dodaniem jednego indywiduum rośnie o 2.77544 ln(2) k_B. Jakiś taki entropijny potencjał chemiczny.
Potrzeba m bitów żeby wybrać jedną z 2^m możliwości - czyli można się też patrzeć, że z dodaniem jednego indywiduum, ilość możliwości rośnie 2^2.77544~=6.84685 raza (ale nie są to liczby naturalne).
|
|
| | | sceptymucha (moderator, 11470 punktów) | Dobra, to zapytam inaczej, bo nie jestem pewien odpowiedzi (czy dobrze się rozumiemy).
Mamy x1 węzłów na poziomie 1, x2 na poziomie 2, xk na poziomie k, x(k+1) na poziomie k+1. Jak się ma x(k+1)/xk?
Pozdrawiam
Człowiek zawsze znajdzie coś nowego w obcym języku. Dziś poznałem nowe pojęcie:
"Negative IQ"
|
|
| | | | Jarek Duda (1185 punktów) | W pełnym drzewie binarnym mamy 1 węzeł na poziomie 0 (korzeń), 2 na poziomie 1 .. 2^k na poziomie k.
W takim losowym drzewie prefixowym te poziomy nie są w pełni wypełnione, czyli tych węzłów jest trochę mniej ... np. średnia głębokość liści jest asymptotycznie o 1.33275 większa niż dla pełnego drzewa.
Ale tu mówimy o czymś innym - nie własnościach pojedynczego drzewa, tylko ich zespołu statystycznego.
Zastanawiam się gdzie można by szukać w przyrodzie tej entropii indywidualności ...
Zachowanie mrówki raczej nie zależy od tego z którym z "braci" ma do czynienia ... może można jej szukać w entropii społeczeństw traktujących jednostki indywidualnie.
Społeczeństwa zwykle nie mają konkretnej kolejności ich jednostek, co kosztowałoby dużo więcej entropii (lg(n!) ~ n lg(n)) niż sama rozróżnialność.
|
|
| | | | ekologik (1240 punktów)
(zablokowany) | Rozumiem, że opisujesz "masę" opisu "drzewa" łapiącego wszystkie przypadki, a raczej jej przyrastanie. Czy możesz to przedstawić na killku konkretnych przykładach, raczej skrajnych, i pokazać, który Cię "zdumiewa" i czemu? Bez wzorów. Bo z tego co wiem, są wybitni naukowcy, którzy wnioski swoich odkryć (i uzasadnienie emocji z nimi związanych) potrafią przedstawić "ludzkim" językiem i ... takich naśladujmy  Ja wyobrażam sobie np a) zbiór wszystkich ziarenek piasku na Saharze (i właśnie jedno rozpadło się na dwa - przyjmijmy, że są możliwe minimalne i najwyżej 12.00(0) razy większe). b) zbiór wszystkich zdań z wszystkich książek i czasopism w języku angielskim (pod warunkiem że nie dłuższych niż 1000 słów - dłuższe odrzucamy) i ktoś dopisał jedno kolejne inne od wszystkich właśnie. c) zbiór wszystkich ludzi w sytuacji za XXXX lat gdy będzie nas w tej cześci Drogi Mlecznej 1000 Miliardów i urodzi się nowy obywatel (a raczej dożyje 36-mca - patrz dalej!) I co tu będzie najbardziej interesujące oraz przy jakich założeniach ? (czy nie ma znaczenia ile aspektów biomedycznych człowieka opisujemy i czy arbitralny wybór ilości tych cech nie "rozwala" wniosków; Ilość badań laboratryjnych, które dziś propnują prywatne i państwowe laboratoria rośnie w ogromnym tempie; Ludzkość za wspomniane XXXX lat moze pozwolić sobie na badanie ludzi na wszystkie sobie znane; Ale - zarazem - co miesiąc dodawać nowe do listy rutynowo wykonywanych badań na 36 miesiacznym brzdącu - nie zapominając - rzecz jasna o wzroście i wadze  No i jeszcze przypadek odwrotny gdy nagle ludkość ówczasna zbiedniała i wyrzuca połowe badań i wnioski z nich) Jeżeli rysuje Ci się jakiś niebanalny wniosek natury filozoficznej to też napisz - prostym językiem(zapewne i jego warto z przykładem). Pozdrawiam
|
|
| | | | | | Jarek Duda (1185 punktów) | Chodzi o stopień złożoności układu - jak skomplikowane są relacje wewnątrz niego. Na przykład (rozwinę to co napisałem sceptymusze poniżej): - jak masz bardzo skomplikowany system jak np. ludzkość, z perspektywy społecznej istotne jest zachowanie interakcji jednostek w różnych grupach, których ilość rośnie jak 2^n - potencjalnie każda z nich wymaga opisu, więc tak też rośnie złożoność systemu, - jeśli istotne są tylko relacje między parami jednostek, takich par jest prawie n^2, tak też rośnie złożoność systemu, - jeśli istotna jest tylko kolejność obiektów, ilość możliwości rośnie jak n!, czyli ilość istotnej informacji jak n!~nlg(n), ... a jeśli istotna jest tylko rozróżnialność elementów, stopień złożoności układu rośnie jeszcze wolniej - liniowo: 2.77544n Z perspektywy fizyki statystycznej powinno się to przekładać na dynamikę, szczególnie interakcji układów o różnej złożoności ... ale nie mam jeszcze pomysłu na konkretny przykład ...? Co to znaczy z perspektyw filozoficznej? Np. chyba że musimy wnieść do społeczeństwa minimum 2.77544 bita żeby się wyróżniać??  No nie jest to zbyt trudne - większość dostarczamy samą rozbudową drzewa genealogicznego ludzkości 
|
|
| | | | | | ekologik (1240 punktów)
(zablokowany) | czy te 2.7 to tendencja statystyczna czy minimum absolutne
(nowy egzemplarz zawsze wnosi co najmniej 2.77 albo zero)?
Weźmy opisaną przeze mnie ewidencję różnorodności (nie ludzi - to kumam!) 100 mld ludzi.
Czy nie może urodzić się człowiek, że wszystkie wyniki będzie miał podobne,
a jeden w taki sposób inny, że "wzbogaci" "drzewo" tylko jednym bitem czy dwoma?
A co jak 100 mld pierwszy człowiek urodzi sie bardzo nietypowy - większość wynikow badan UNIKALNA
czy "drzewo" urośnie nagle o tysiące bitów - przez jednego niezwykłego człowieka ?
|
|
| | | | | | | | Jarek Duda (1185 punktów) | To jest tylko potencjalne dolne ograniczenie na rozróżnialność po indywidualnych cechach ... jak najbardziej zwykle osobnik wnosi nieporównywalnie więcej.
Przy tej granicy możemy pracować na komputerze, ale w przyrodzie chyba trudno o system działający w pobliżu...?
|
|
| | | | | sceptymucha (moderator, 11470 punktów) | >W pełnym drzewie binarnym mamy 1 węzeł na poziomie 0 (korzeń), 2 na poziomie 1 .. 2^k na poziomie k.
>W takim losowym drzewie prefixowym te poziomy nie są w pełni wypełnione, czyli tych węzłów jest trochę mniej ...
O to mi chodzi! O ile jest mniej!
> np. średnia głębokość liści jest asymptotycznie o 1.33275 większa niż dla pełnego drzewa.
To sobie poprzeliczam, zobaczę czy da mi coś ta informacja. Wolałbym tą z porównania węzłów na różnych poziomach.
>Ale tu mówimy o czymś innym - nie własnościach pojedynczego drzewa, tylko ich zespołu statystycznego.
Zespół statystyczny to też drzewo, tylko złożone z drzewek. Zbadanie kilku drzewek coś mogłoby powiedzieć o całym zespole (to się chyba nawet nazywa próba losowa, test wiarygodności).
>Zastanawiam się gdzie można by szukać w przyrodzie tej entropii indywidualności ...
Wszędzie, gdzie masz procesy czysto losowe. W przyrodzie ożywionej będzie ciężko, bo tu są powiązania.
W komunikacji masz problem z przesyłaniem informacji (też Shannon nad tym siedział), albo z szukaniem sygnału od kosmitów w szumie. Na tem moment więcej nie przychodzi mi do głowy.
Pozdrawiam
Człowiek zawsze znajdzie coś nowego w obcym języku. Dziś poznałem nowe pojęcie:
"Negative IQ"
|
|
| | | | | | Jarek Duda (1185 punktów) | >>W pełnym drzewie binarnym mamy 1 węzeł na poziomie 0 (korzeń), 2 na poziomie 1 .. 2^k na poziomie k.
>>W takim losowym drzewie prefixowym te poziomy nie są w pełni wypełnione, czyli tych węzłów jest trochę mniej ...
>O to mi chodzi! O ile jest mniej!
Nie widzę motywacji, ale nie ma problemu policzyć.
Na poziomie d jest potencjalnie 2^d możliwości. Prawdopodobieństwo że konkretne z nich nie będzie obsadzone przez żaden z n losowych ciągów, to (1-2^(-d))^n
Czyli obsadzonych węzłów będzie średnio 2^d(1-(1-2^(-d))^n)
>To sobie poprzeliczam, zobaczę czy da mi coś ta informacja. Wolałbym tą z porównania węzłów na różnych poziomach.
Raczej wszystko można względnie łatwo policzyć, np. w takim drzewie D_n^d procentowo liści będzie miało głębokość d:
D_n^d=(1-2^(-d))^(n-1)-(1-2^(-d+1))^(n-1)
>>Ale tu mówimy o czymś innym - nie własnościach pojedynczego drzewa, tylko ich zespołu statystycznego.
>Zespół statystyczny to też drzewo, tylko złożone z drzewek. Zbadanie kilku drzewek coś mogłoby powiedzieć o całym zespole (to się chyba nawet nazywa próba losowa, test wiarygodności).
Ja bym to raczej nazwał zbiorem drzew (tym razem nieskończonym), w którym do każdego elementu przyporządkowujemy prawdopodobieństwo.
Czy na tym zbiorze można wprowadzić strukturę drzewiastą to osobny i w sumie dość praktyczny problem jeśli chcielibyśmy np. pracować na takiej strukturze funkcji hashujących w czasie rzeczywistym.
Jeśli to drzewo drzew miałoby większość węzłów o stopniu 2, to rzeczywiście ŚREDNIA odległość od korzenia byłaby ową entropią (rosnącą 2.77544 binarnych wyborów na element).
Z podkreśleniem na słowo średnia - jako że rozmiar tego zbioru jest nieskończoność (nawet dla n=2 jak na obrazku), byłyby w nim ścieżki dowolnie dużej długości, tyle że ich prawdopodobieństwo maleje do zera, czyli też przyczynek do średniej.
>>Zastanawiam się gdzie można by szukać w przyrodzie tej entropii indywidualności ...
>Wszędzie, gdzie masz procesy czysto losowe. W przyrodzie ożywionej będzie ciężko, bo tu są powiązania.
>W komunikacji masz problem z przesyłaniem informacji (też Shannon nad tym siedział), albo z szukaniem sygnału od kosmitów w szumie. Na tem moment więcej nie przychodzi mi do głowy.
Mówimy tutaj o czymś bardzo subtelnym - o złożoności systemu:
- gdy istotna jest tylko ilość nierozróżnialnych elementów, rośnie ona jakoś jak lg(n)
- gdy dochodzi rozróżnialność elementów, rośnie liniowo ze współczynnikiem 2.77544
- gdy istotna jest kolejność elementów, zaczyna rosnąć dość szybko (lg(n!)~nlg(n))
- gdy istotne są relacje między parami elementów, rośnie z n^2
- gdy istotne są relacje w dowolnych grupach, rośnie z 2^n
Z fizyki dobrze znamy coś co nawet nazywa się czasem siłą entropową - statystyczny pęd do nieporządku - zgodny z drugą zasadą termodynamiki. Jak gdy cały gaz znajduje się w jednej połowie naczynia, pojawia się jakby siła dążąca do rozdystrybuowania go po całym naczyniu.
Podobnie ze stopniem skomplikowania systemu - należenie do jednej z powyższych klas powinno przekładać się na jego dynamikę.
|
|
| | | | | | | sceptymucha (moderator, 11470 punktów) | >>>W pełnym drzewie binarnym mamy 1 węzeł na poziomie 0 (korzeń), 2 na poziomie 1 .. 2^k na poziomie k.
>>>W takim losowym drzewie prefixowym te poziomy nie są w pełni wypełnione, czyli tych węzłów jest trochę mniej ...
>>O to mi chodzi! O ile jest mniej!
>Nie widzę motywacji, ale nie ma problemu policzyć.
>Na poziomie d jest potencjalnie 2^d możliwości. Prawdopodobieństwo że konkretne z nich nie będzie obsadzone przez żaden z n losowych ciągów, to (1-2^(-d))^n
Ok. Czyli na poziomie (d+1) jest (1-2^(-d-1))^n. Porównując poziomy do siebie mamy poziom(d+1)/poziom_d = [1 + (1/2)^d/(1-(1/2)^d)]^n, co przy dążeniu do nieskończoności może dążyć do liczby Eulera e, lub stałej, która Ci wyszła.
>Czyli obsadzonych węzłów będzie średnio 2^d(1-(1-2^(-d))^n)
Tego nie rozumiem. Bardziej pasuje mi tak (2^d)*(1-(1-2^(-d))^n)?
Pozdrawiam
Człowiek zawsze znajdzie coś nowego w obcym języku. Dziś poznałem nowe pojęcie:
"Negative IQ"
|
|
| | | | | | | | Jarek Duda (1185 punktów) | Przepraszam, pomyliłem się - żeby dana z 2^d możliwości była węzłem wewnętrznym minimalnego drzewa prefixowego (nie liściem), muszą do niej dotrzeć przynajmniej 2 sekwencje (nie 0 ani 1), czyli obsadzonych węzłów na poziomie d będzie średnio:
2^d * (1 - (1-2^(-d))^n - n*2^(-d)*(1-2^(-d))^(n-1))
|
|
| | | | | | | | Jarek Duda (1185 punktów) | Pytałeś się ile jest różnych węzłów - dzięki popracowaniu nad redukcją mam przeliczone jeszcze kilka rzeczy (w zaktualizowanej pracy): np. jak wiemy że węzłów stopnia 2 jest n-1, okazuje się że ilość węzłów o stopniu 1 też rośnie liniowo: jak n*lg(e/2)~0.44269n
|
|
| | | | | | | | | sceptymucha (moderator, 11470 punktów) | >Pytałeś się ile jest różnych węzłów - dzięki popracowaniu nad redukcją mam przeliczone jeszcze kilka rzeczy (w zaktualizowanej pracy): np. jak wiemy że węzłów stopnia 2 jest n-1, okazuje się że ilość węzłów o stopniu 1 też rośnie liniowo: jak n*lg(e/2)~0.44269n
Jak będę miał chwilę, to wrócę do tematu - w tym momencie mogę powiedzieć, że przemyślę rzecz.
Pozdrawiam
Hmm. Tak. Jestem pewien. Chyba jestem pewien. Raczej tak. Hmm.
|
|
Hetman Twardowski (482 punktów)
(zablokowany) | A to nie jest przypadkiem kodowanie Huffmana?
Tam są budowane takie ścieżki - prefiksy.
Jeśli tak, to te 2.7 bitów nie jest minimum, ponieważ kodowanie arytmetyczne jest silniejsze od Huffmana.
>Czyli to równanie mówi:
>rozróżnialność/indywidualność + porządek = całkowita ilość informacji
>rozróżnialność średnio rośnie liniowo z n (z asymptotycznym współczynnikiem 2.77544)
>informacja o porządku rośnie szybciej: lg(n!) ~= n lg(n) - n lg(e).
>Jak rozumieć taką minimalną ilość informacji potrzebną na rozróżnianie elementów układu?
>Czy można zaobserwować taki współczynnik wzrostu entropii z wzrostem populacji?
>Może ktoś się kiedyś spotkał z czymś podobnym?
W naturze/fizyce o złożoności systemu chyba decyduje liczba hierarchii.
Społeczeństwo jest bardzo złożoną strukturą ponieważ jest tu właśnie od groma hierarchii: poczynając od atomów, poprzez związki chemiczne, białka, różne łańcuchy, potem wyspecjalizowane tkanki, organy, dalej organizmy = jednostki, i znowu: ich pary, specjalistyczne grupy, instytucje, organy, itd.
|
|
| | Jarek Duda (1185 punktów) | > A to nie jest przypadkiem kodowanie Huffmana?> Tam są budowane takie ścieżki - prefiksy.> Jeśli tak, to te 2.7 bitów nie jest minimum, ponieważ kodowanie arytmetyczne jest silniejsze od Huffmana.Kodowanie Huffmana to wybór drzewa binarnego dla danego rozkładu prawdopodobieństwa żeby zbliżyć się do entropii Shannona. "Silniejsze" w sensie bliżej tego optimum, a nawet dowolnie blisko - podobnie jak prostsze asymetryczne systemy liczbowe (jeden stan zamiast dwóch). Tutaj od razu pytam się o entropię Shannona ... trochę innego problemu. > Społeczeństwo jest bardzo złożoną strukturą ponieważ jest tu właśnie od groma hierarchii: poczynając od atomów, poprzez związki chemiczne, białka, różne łańcuchy, potem wyspecjalizowane tkanki, organy, dalej organizmy = jednostki, i znowu: ich pary, specjalistyczne grupy, instytucje, organy, itd.Pytanie o minimalną entropię dla danego typu złożoności - jakieś lg(n) jeśli obiekty są nierozróżnialne, n!~nlg(n) jeśli istotna jest ich kolejność ... pomiędzy powinien być przypadek gdy istotna jest tylko nierozróżnialność elementów - i okazuje się że rzeczywiście: entropia rośnie liniowo 2.77544 w tym przypadku.
|
|
| | Hetman Twardowski (482 punktów)
(zablokowany) | >Pytanie o minimalną entropię dla danego typu złożoności - jakieś lg(n) jeśli obiekty są nierozróżnialne, n!~nlg(n) jeśli istotna jest ich kolejność ... pomiędzy powinien być przypadek gdy istotna jest tylko nierozróżnialność elementów - i okazuje się że rzeczywiście: entropia rośnie liniowo 2.77544 w tym przypadku.
A jak można zapisać rozróżnialność?
Wśród ciągów bitów długości n mamy dokładnie 2^n różnych.
suma 1/2^n log 2^n = 1, dla N = 2^n sztuk.
Nie wiem skąd te 2.77 - chyba jakieś marnotrawne kodowanie...
|
|
| | | | Jarek Duda (1185 punktów) | Nie rozumiem co daje te 2^n?
2.77544/ciąg jest z zakodowania drzewa n potencjalnie nieskończonych ciągów (minimalnego rozróżniającego drzewa).
|
|
| | | | Hetman Twardowski (482 punktów)
(zablokowany) | >Nie rozumiem co daje te 2^n?
>2.77544/ciąg jest z zakodowania drzewa n potencjalnie nieskończonych ciągów (minimalnego rozróżniającego drzewa).
Ale na czym właściwie ma polegać takie kodowanie drzewa, i co tam jest kodowane?
n bitów daje dokładnie 2^n rozróżnialnych - pamięć asocjacyjna, itp.
|
|
| | | | | | Jarek Duda (1185 punktów) | Z przestrzeni wszystkich możliwych drzew wybieramy jedno konkretne.
Dla 2 liści rozkład prawdopodobieństwa na tej nieskończonej przestrzeni jak na rysunku z pierwszego posta zaczyna się od:
(1/2,1/8,1/8,1/32,1/32,1/32,1/32,1/128,... )
|
|
| | | | | | Hetman Twardowski (482 punktów)
(zablokowany) | >Z przestrzeni wszystkich możliwych drzew wybieramy jedno konkretne.
>Dla 2 liści rozkład prawdopodobieństwa na tej nieskończonej przestrzeni jak na rysunku z pierwszego posta zaczyna się od:
>(1/2,1/8,1/8,1/32,1/32,1/32,1/32,1/128,... )
Nie wiem co jest... pewnie zwyczajna średnia w kodowaniu Huffmana.
|
|
| | | | | | | | Jarek Duda (1185 punktów) | Dzięki temu że prawdopodobieństwa w tym przypadku są potęgami 2, rzeczywiście tym razem moglibyśmy optymalnie zakodować (i to dość prosto) wybór jednego z nich drzewkiem Huffmana. Dla 3 elementów już nie jest tak prosto.
|
|
| | | | | | | | Hetman Twardowski (482 punktów)
(zablokowany) | >Dzięki temu że prawdopodobieństwa w tym przypadku są potęgami 2, rzeczywiście tym razem moglibyśmy optymalnie zakodować (i to dość prosto) wybór jednego z nich drzewkiem Huffmana. Dla 3 elementów już nie jest tak prosto.
Ale w kodowaniu arytmetycznym nie ma takich ograniczeń i stąd ta przewaga.
A nierozróżnialności jest chyba tylko umowna, znaczy to samo można wyliczyć z rozróżnialnych (na tym właśnie opiera się pojęcie entropii, rozumianej jako miara ignorancji).
|
|
| Jarek Duda (1185 punktów) | W dzisiejszych czasach nawet indywidualność ulega dewaluacji - do ok. 2.3327464 bita na element/osobnik (dzięki Jamesowi Dow Allenowi): groups.goo(*)c/comp.compression/j7i-eTXR14EAle to już chyba cena ostateczna - dalej zbić się już nie da. Mianowice dla minimalnego drzewa prefixowego, losowy ciąg (reprezentujący indywidualne cechy osobnika) ma prawdopodobieństwo ok. ln(2)~0.721 na bycie zaklasyfikowany jako należący do populacji ... czyli jeśli interesuje nas tylko rozróżnialność, możemy sobie pozwolić na powiększenie tego prawdopodobieństwa do 1 (dalej się nie da). Żeby zredukować ilość informacji w minimalnym drzewie prefixowym, zauważmy że gdy występuje w nim węzeł o stopniu 1, znaczy się że wszystkie osobniki które tam doszły, na pewno pójdą w danym kierunku - będąc pewnym że poruszamy się wśród osobników danej populacji, możemy oszczędzić ten bit informacji o kierunku w takim węźle. W minimalnym drzewie prefixowym te węzły o stopniu 1 były miejscami gdzie mogło się okazać że osobnik nie należy do populacji - usuwając tą informację zwiększamy prawdopodobieństwo błędnego pozytywnego zaklasyfikowania z 0.721 do 1. Czyli jak dla ciągów (0101.., 1010.., 1001..), minimalne drzewo prefixowe pamięta (bez porządku!): (0....., 101..., 100...), natomiast takie zredukowane pamięta tylko (0....., 1.1..., 1.0...) Co zmniejsza jego asymptotyczny koszt z 2.77544 bitów/element do ok. 3/2 + gamma*lg(e) ~ 2.3327461772768672 bitów/element.
|
|
Aby pisać w tym wątku, musisz się zalogować
Zaloguj przez OpenID..
Jeżeli nie jesteś zarejestrowany/a - załóż konto..
Szukaj na Forum Przewodnik Regulamin i instrukcja obsługi Forum Kolegium Moderatorów

|
 |
|
